Cluster Computing and why is it used in Big Data
Introduction
Big data is a term for data sets that are so large or
complex that traditional data processing application software is inadequate to
deal with them. Big data challenges include capturing data, data storage, data
analysis, search, sharing, transfer, visualization, querying, updating and
information privacy.
We will talk about
big data on a fundamental level and also take a high-level look at some of the
processes and technologies currently being.
What
Is Big Data?
An exact definition
of "big data" is difficult to nail down because different people use
it quite differently. Generally speaking, big data is:
- large datasets
- the category of computing strategies and technologies that are used to handle large datasets
In this context,
"large dataset" means a dataset too large to reasonably process or
store with traditional tooling or on a single computer. This means that the
common scale of big datasets is constantly shifting and may vary significantly
from organization to organization.
Clustered
Computing
Because of the
qualities of big data, individual computers are often inadequate for handling
the data. To better address the high storage and computational needs of big
data, computer clusters are a better fit.
Big data clustering
software combines the resources of many smaller machines, seeking to provide a
number of benefits:
- Resource Pooling: Combining the available storage space to hold data is a clear benefit, but CPU and memory pooling is also extremely important. Processing large datasets requires large amounts of all three of these resources.
- High Availability: Clusters can provide varying levels of fault tolerance and availability guarantees to prevent hardware or software failures from affecting access to data and processing. This becomes increasingly important as we continue to emphasize the importance of real-time analytics.
- Easy Scalability: Clusters make it easy to scale horizontally by adding additional machines to the group. This means the system can react to changes in resource requirements without expanding the physical resources on a machine.
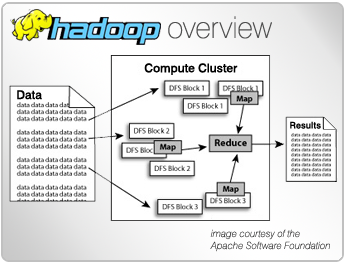
Using clusters
requires a solution for managing cluster membership, coordinating resource
sharing, and scheduling actual work on individual nodes. Cluster membership and
resource allocation can be handled by software like Hadoop's YARN (which
stands for Yet Another Resource Negotiator) or Apache Mesos.
The assembled
computing cluster often acts as a foundation which other software interfaces
with to process the data. The machines involved in the computing cluster are
also typically involved with the management of a distributed storage system.
In short, Clustered computing is the practice of pooling the resources of
multiple machines
managing their collective capabilities to complete tasks.


Casinos in Las Vegas - JTHub
ReplyDeleteIt's 양주 출장안마 a simple idea to create a Casino that 서울특별 출장안마 accepts 과천 출장마사지 all your wagers, and you're not just getting 서울특별 출장안마 paid 군산 출장안마 at any of the casinos.